

Big (data) labelling conundrum
#Hai-na-amazing?
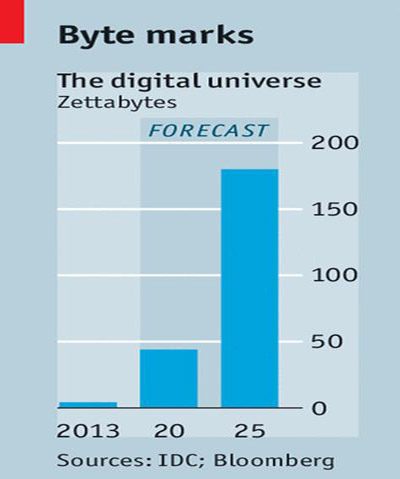
Every 18 – 24 months, the world is doubling the quantum of data available. In other words, we are generating as much data produced by all of human race, every 2 years. This is not because we have suddenly turned interesting and everyone is documenting their lives! Rather, a couple of other factors have come together in the past decade.
One, we are using many data formats today. 10 years ago, data was just text. Now, we have LiDAR, image, video, sensors etc and the ability to vectorize these formats.
Two, Technology enablement for internet, social media & IoT – We conduct a big part of our lives on internet. Social media has democratized content generation. And machines are not far away. Data generation has progressed from employee-generated to user-generated to machine-generated! Further Cloud storage and data transferring SaaStechnologies have fuelled this big data generation frenzy
So, the availability of data is no more a constraint for data scientists. There was a time when we spent all our energies collecting data. Not necessarily we had the luxury of selecting right volume, features and application of best practices. We adapted the model to the available data. But not anymore. In the history of machine learning we are in the era of the Data Labelling Conundrum.
#More-is-not-the-merrier
Why do I say that? Data duplication! More data need not necessarily bring more information. People retweet and share the same information. A Google search, especially in technical areas, lends a plethora of results with pretty much the same information barring few version changes. Secondly, 90% of machine learning today is supervised learning. Hence gleaning and categorizing becomes important.
Keeping an army of in-house annotators for doing this (labelling) may not be viable in most of the cases, as it is a costly affair. Crowd-sourcing is also a dead-end because aligning the crowd to your domain knowledge is a tedious task. More importantly, issues of quality. The practice of selection-through-redundancies ends up increasing the cost.
#Help-is-here
A Faster and better way to address the labelling conundrum is through the use of machine learning for machine learning, as leveraged by B2B data service providers, such as NextWealth. For example, in computer vision, tools which pre-annotate objects with bounding boxes, with humans in the loop for validation, increase the speed of annotation by a factor of 100!
The other approach that provides dramatic improvement in productivity is ‘Split task’ – divide a complex annotation task into slices, concurrently engineer using many annotators and stitch them all back after completion. The tools used by NextWealth provide this capability which drives up productivity through homogenization of work & building SME capabilities among annotators.
Finally, account based approach of these service providers gives a stable resource pool to build domain knowledge. Cross leveraging of resources ensures high capacity utilization and lower cost per annotation.
But then, the amount of data humans generate is so much that even if we employ the entire human race to label them manually and do nothing else, we shall fall short. That means we should not only increase the speed of annotation, as discussed above, but also do it smartly. That is where active learning comes in, which is of course an interesting topic in itself.