

Missing the cold-war era big time!
I can see that data scientists miss the space race of the Cold War big time! At least in the way that an unlimited budget was available to develop new technologies. Alas, today they need to walk a tight rope to produce models with high accuracy that remain within the budget!
Do not spray in the dark!
It is common knowledge that more the quantum of data used to train a machine learning algorithm, better the accuracy. However, getting a large volume of data labelled is a costly affair. Traditional machine learning model development uses random sampling to select the data to be labelled. Instead, if we could use a certain intelligence and select only that data which contains maximum knowledge to be learnt, we may hit two mangoes in one stroke – one, the training will take lesser time to achieve similar accuracy and two, more importantly, the budget for labelling will be optimized.
This smart way to reduce the quantum of data to be labelled is Active Learning.
The magic wand – What is Active Learning?
Selecting the most informative rows in the dataset for labelling in order to optimize the ratio of information to data volume is called Active Learning. In other words, spending money on labelling only that data that gives maximum bang for the buck. It is done in 5 steps
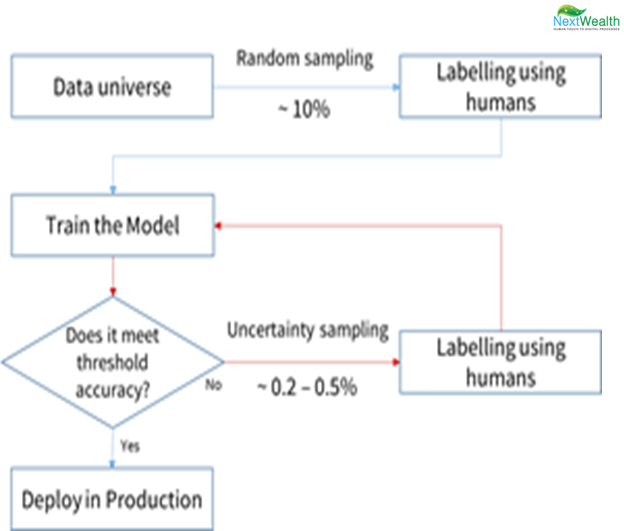
Step 1 : Select a sample from the dataset universe either randomly or using relevant domain intelligence. It could be as low as 10% to 15% of the dataset
Step 2 : Bring humans into the loop and get them to assign high quality labels to the data
Step 3 : Train the learner (model) using this labelled dataset
Step 4 : Test the learner with unseen data. If the accuracy is above our threshold, deploy it in production
Step 5 : Otherwise, select a small set (0.2 to 0.5%) from the unseen data used in step 4 and send it to be labelled by humans. Then, repeat step 3 till we achieve the desired accuracy
The Secret
The question is, “How do we know which data is the most efficient to iterate in step 5?
If you are preparing for an exam, which one is the smarter way – spending time on thorough topics or picking those areas where you are doubtful? The exact same approach can be used to make a model learn efficiently as well. Label only those data points about which the model is doubtful and use them for training. There are multiple ways to measure the “doubt” of the model –
- Typically, those data points which fall next to the decision or class boundaries are hard to learn and are thus selected. The distance from the hyper plane in SVMs, the probability of occurrence in a probabilistic model and so on, give away these hard data points.
- Those data-points whose inclusion brings about the maximum change in the model, for example in gradient loss function.
- Those data points that result in maximum reduction of the generalization error.
- Or give weights to the typicality of data with respect to the entire unlabelled pool and use the information to select appropriately.
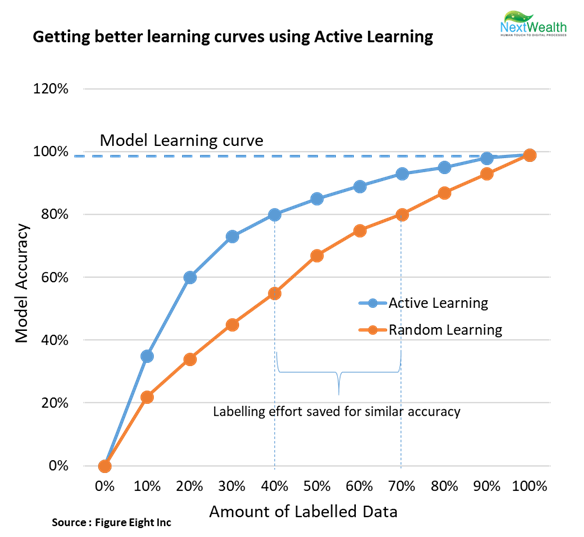
In an object recognition problem, we can make the iteration sample with 30% from lower confidence scores of the positive class, 70% from top confidence scores of the negative class. Some papers report that 99% of the accuracy achieved through traditional methods is reached with just 25% of the data.
A key aspect seldom emphasized is the benefit of having a constant team supporting labelling, throughout the Active Learning iterations. Data scientists benefit significantly from the feedback received from the B2B managed data service providers, such as NextWealth, to fine tune their uncertainty sampling strategies.
Leave a Reply